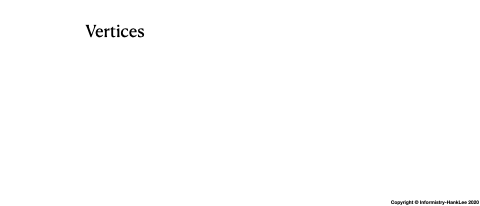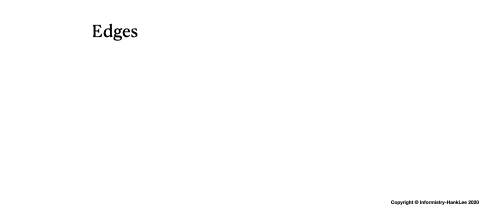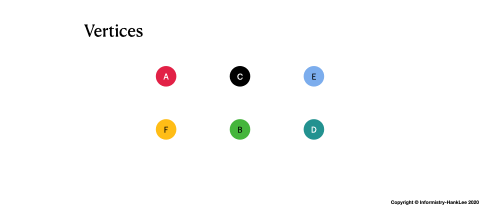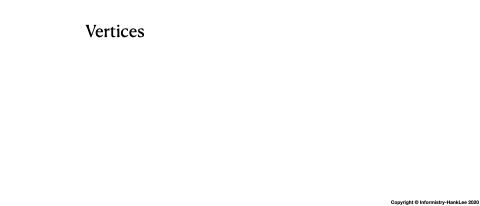本系列文章同步分享於個人Blog → Informistry-HankLee
第二天我們介紹了針對演算法執行效率(Time Complexity)進行了說明,然而除了當中提到的Basic Operation和Input Size會影響Time Complexity之外,資料本身的結構也是相當重要的。在真正介紹幾個比較常用的資料結構之前,今天會先介紹抽象資料型別(Abstract Data Type)及其特性。
演算法在解析、處理資料時,可能會需要將原先的資料轉換成不同的資料形式進行處理,最後再以資料的樣態產出結果來儲存,然而我們在設計與分析演算法的時候,通常Input data的資料型態是固定的,我們並不會針對一個演算法考慮所有不同的Input資料型態,取而代之的是針對資料的一般特性(general characteristics)與操作方式(operations) 進行討論,而這種資料的抽象化就是抽象資料型別(Abstract Data Type)。
在電腦科學中,抽象資料型別(Abstract Data Type)是一種理論上的觀念,它主要是用於設計與分析演算法、資料結構及軟體系統當中,而一個抽象資料型別通常定義了資料型別(values)和操作方式(operations),舉例來說,整數(Integer)就是一個抽象資料型別,他定義了在這個ADT底下,其資料型別(value)為整數(-2, -1, 0, 1, 2等)且操作方式(operation)有加、減、乘、除等。此外,抽象資料型別的這個概念並沒有限定於特定的程式語言,換言之,不同的程式語言都可以實作抽象資料型別的概念,而且單一種ADT也可以透過多種不同的方式來進行實作,例如Bit vectors或Hexadecimal vectors這兩種資料結構都是Integer的實作(Implementation)。
下面將會針對八種比較常見的抽象資料型別一一介紹:
Set中只會出現一次(不會重複)Set中若一個物件可能出現多次,那這樣的集合稱為Multiset
以Key-Value組合的集合物件(Collection)
每個Key在一個Collection中只會出現一次
時常用來作為傳遞資料的JSON也常以Dictionary/Map的方式來存放資料
範例:
| Key | Value |
|---|
brand|Honda
color|Red
body_type|Hatch
Stack不同,Queue就像排隊一樣,先進到隊伍中的項目(First In)就會優先被取用(First Out)Queue相同,但是每個Elements都會自帶一個『優先度』(priority)Queue的的方式相同Graph
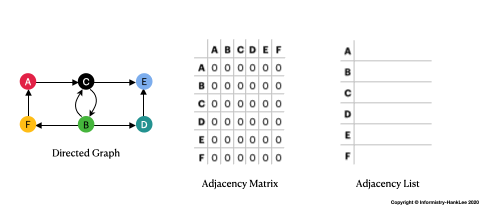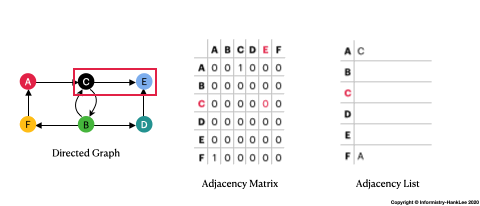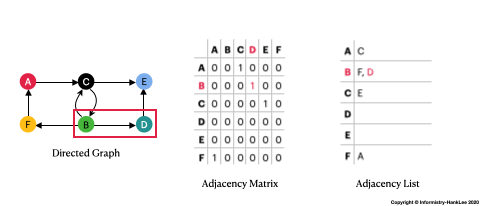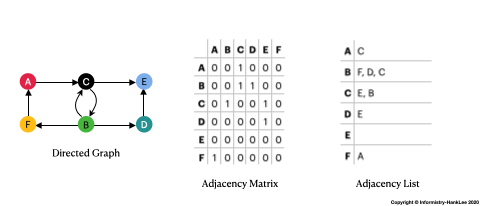
Graph是由 節點(Vertices)和關聯(Edges) 組合而成,以上圖為例:
Graph又可分為兩種:

Graph呢?基本上方法也有兩種:
1,其餘則為0。

Tree也是一種GraphTree是沒有環形(acyclic)的GraphTree有一個特性是Graph沒有的:Edges的數量永遠會是Vertices的數量減1(|E| = |V| -1)
Tree可分為兩種:

Free Tree轉換成Rooted Tree,會由其中一個Node作為Root,再由其往下延伸、串接。Rooted Tree的好處是它的『階層關係』,至於這個『階層關係』所代表的意義,就看實作時要賦予它什麼意義了,可以是『大小』、『相似度』等。
抽象資料型別(Abstract Data Type, ADT)是一種理論上的概念,可藉由不同的Data Structure來實作。
8種常見的ADT:
| No. | ADT | 重點 |
|---|
1|Set|每個物件只會出現一次,且無順序性
2|Sequences/List|每個物件可出現多次,且有順序性
3|Dictionary/Map|key-value pairs的集合物件,Key在此集合物件中不會重複
4|Stack|Last In, First Out(LIFO)
5|Queue|First In, First Out(FIFO)
6|Priority Queue|有優先等級的Queue,在Dequeue時會依照優先等級取值
7|Graph| - 由Vertices和Edges組成 - 可分為Undirected Graph及Directed Graph - 在不畫圖的方式下,可用Adjacency Matrix和Adjacency List表示
8|Tree| - 為沒有環狀的Graph - Edges的數量永遠會是Vertices的數量減1
下一篇將會介紹5種資料結構及其特性。